A unified model for conditional video prediction
Continuous conditional video synthesis by neural processes
Code
Uncurated Examples of the unifed model for each task of VFI, VFP, VPE and VRC
we show prediction examples of 1X fps (original fps of the dataset), 2X fps and 3X fps. 2X fps and 3X fps show the continuous prediction ability of our unified model. Frames with Red temporal coordinates denote frames generated by our model.
Video interpolation (VFI)
1X fps
left column: ground-truth. Right column: predicted videos

2X fps (Ground-truth is not available)

3X fps (Ground-truth is not available)

Video future prediction (VFP)
1X fps
left column: ground-truth. Right column: predicted videos

2X fps (Ground-truth is not available)

3X fps (Ground-truth is not available)

Video past frame extrapolation (VPE)
1X fps
left column: ground-truth. Right column: predicted videos

2X fps (Ground-truth is not available)

3X fps (Ground-truth is not available)

Video random missing frames completion (VRC)
1X fps
left column: ground-truth. Right column: predicted videos

2X fps (Ground-truth is not available)

3X fps (Ground-truth is not available)

VRC with mixing fps (Irregular time step, Ground-truth is not available)
Some missing frames are predicted with 1X fps, some missing frames are predicted with 2X fps, some missing frames are predicted with 3X fps.

Uncurated Examples of task-specific VFI
Frames with Red temporal coordinates denote frames generated by our model.
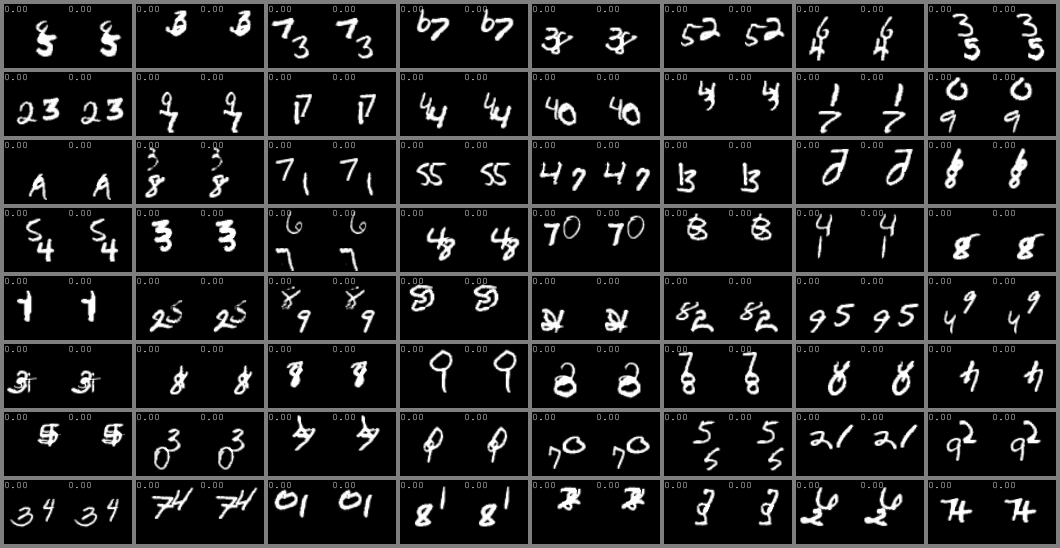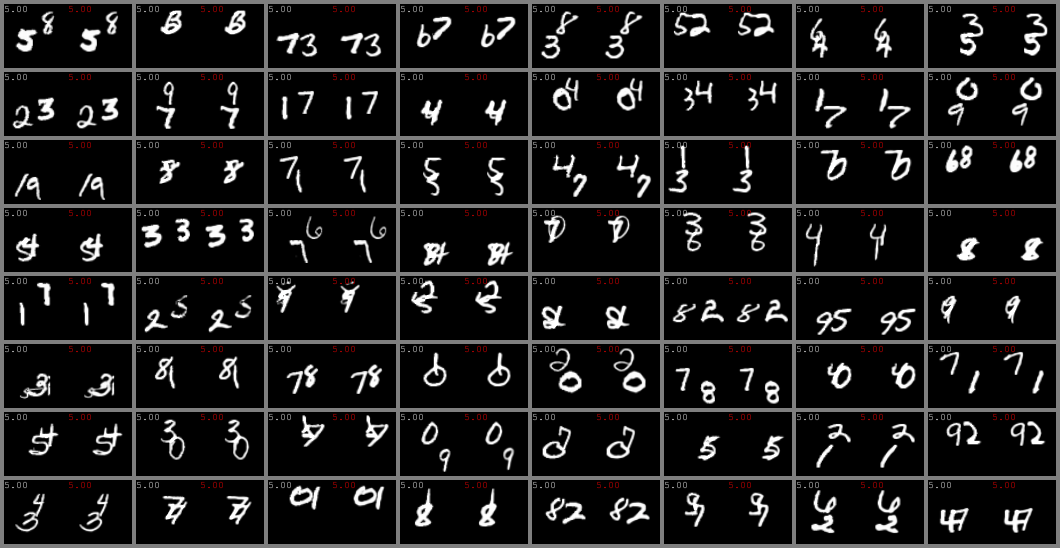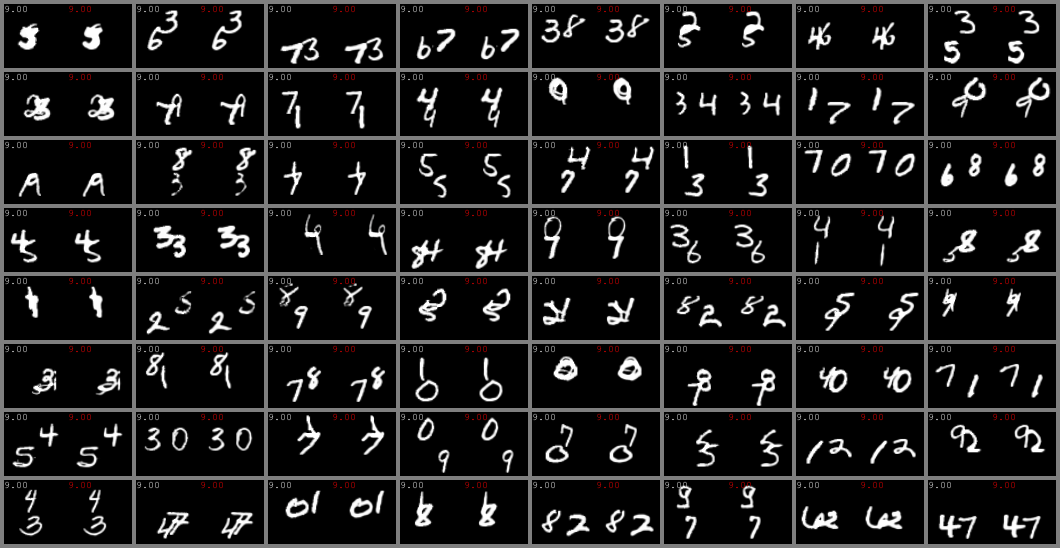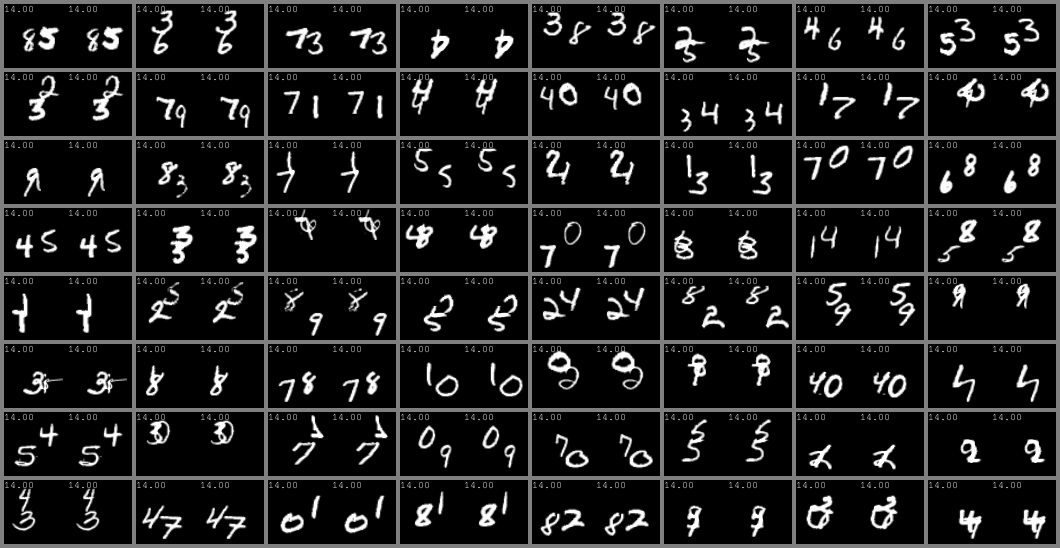
KTH and SM-MNIST (64x64)
left column: ground-truth. Right column: predicted videos.

BAIR (64x64)
left column: ground-truth, middle column: random prediction 1, right column: random prediction 2.

Uncurated Examples of task-specific VFP
Frames with Red temporal coordinates denote frames generated by our model.
KTH (64x64)
left column: ground-truth. Right column: predicted videos.

Cityscapes (128x128)
left column: ground-truth, right column: predicted videos.

KITTI (128X128)
left column: ground-truth, right column: predicted videos.
